

In the world dominated by the IoT and the increasingly demanding users, the applications and the developers itself need to adopt a new paradigm to satisfy those needs. The user's expectations are often very high as they want the contracted IT services highly available and the new feature requirements implemented as soon as possible. Besides that, project managers also want developers to complete the tasks in a time-constrained iterations guaranteeing the quality and good performance of the final product. Despite the increasing size and complexity of the applications, we still need to stay agile and deliver the product in established deadlines. Definitely, not a trivial task, at least not in a monolithic tightly coupled application architectures.
It is where CQRS comes to the rescue. CQRS stands for Command Query Responsibility Segregation, a design pattern with a very simple foundation: divide the application into two parts - one that is responsible for executing actions and other one providing a thin data layer for query execution. So we have two models, the write model and the read model. Although at first glance may seem irrelevant, this approach opens up a plethora of possibilities. To better understand the CQRS paradigm, we will explain each of its building blocks with the help of the diagram below.
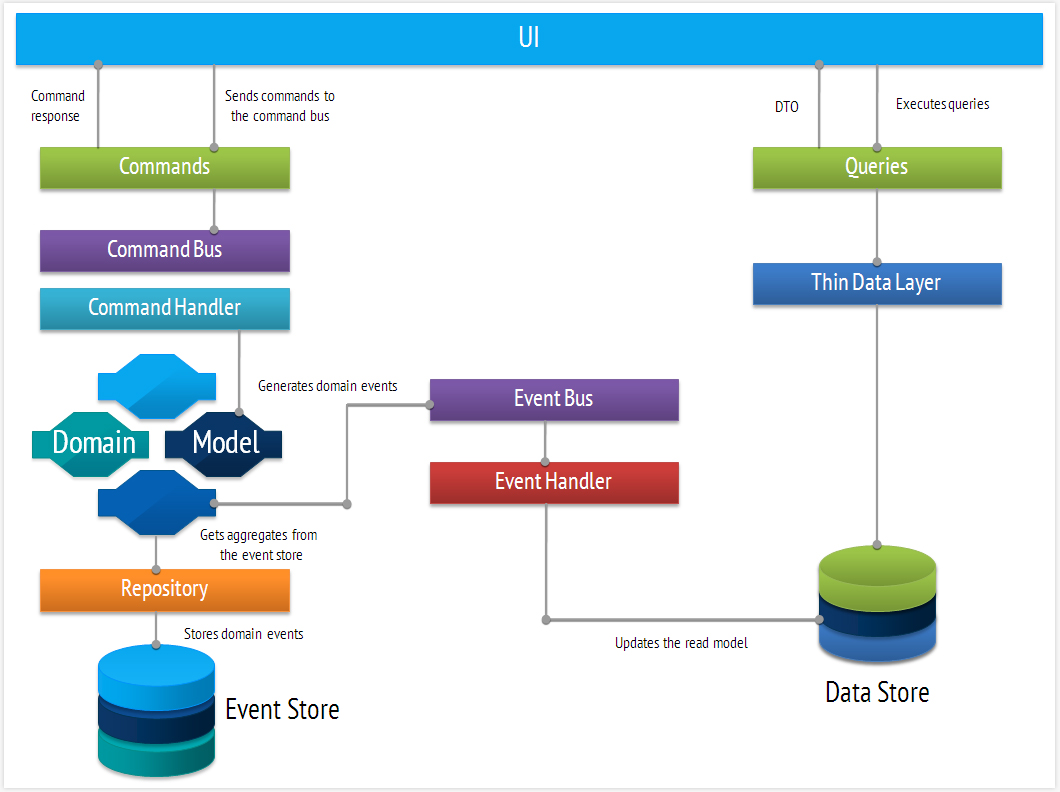
-
Commands are the objects that encapsulate both the user's intention as the information necessary to perform the operation. For example,
CreateNewUserCommandwould hold a variety of attributes such as username, address, age, etc. Commands are sent to the command bus and later dispatched to its corresponding command handler. The state change in the system is started by executing the command. - Domain model represents the heart of the system. Because the CQRS is based on its predecessor DDD (Domain Driven Design) the main design approach resides on the rich domain model. What does this mean? In traditional design, the domain objects often play the role of entities that just keep the system state and lack any kind of behavior, and thus is often called as anemic domain model. This also tends to create ambiguity between the DTO (Data Transfer Objects) and model objects, making the domain model end up having information that must be rendered in the view, and therefore create coupling. The dedicated service layer alters the system state. CQRS promotes a strictly behavior based domain model.
- Repositories provide access to domain objects and allow isolating the domain model from persistence mechanism. Repositories just have to be able to recover the aggregate (domain object) from its unique identifier, while any other type of query is performed against read model.
- Events are the source of any state changes in the application. As mentioned above, executing commands on aggregate, initiates the state change in the system, which in turn will produce a series of domain events. We don't need to persist domain objects but the generated domain events. With this we are able to reconstruct the domain object to its last state, just by applying the stream of events on it. This pattern is known as event sourcing. Events are sent to the event bus, and dispatched to any component interested in consuming it.
- Event store provides a backing store for domain events. Those are often relational databases and NoSQL databases, but for the proof of concepts they can be implemented as file system stores.
- Queries are executed against simple read-only data layer. The information needed to be rendered in the view is reflected in the object which contains the results of the query. We can say that the object is tailored for what view needs to represent.
Advantages of CQRS
- Allows the application to be distributed across multiple physical or virtual machines (horizontal scalability).
- High availability at the application level. If one component fails, the rest of the system can still works.
- Audit / tracking / tracing of user actions out of the box. This type of audit is not comparable to any infrastructure log, since domain events add additional value to the business. It's easy to extract and ingest the domain events into machine-learning platforms or correlation engines, for example to predict user actions, detect anomalies, etc. By having the trace of everything that happens in the application, we have a single source of truth. It is also easier to reproduce the software failures.
- Instead of binding domain objects with UI components, we have simple DTO that accurately reflect what we want to represent in the view and it can be retrieved directly from the database. Thus, we can obtain all necessary information in a single request to the data source.
- CQRS help us to write an expressive domain model. It also puts the models on a "diet" since the models only need to have the attributes relevant for the business decision.
- When the command is about to be processed, the repository will get the stream of events related to the object from the event store. The object state is reconstructed from the event stream. Thus, we get the object in its original state and there will not need to provide persistence to the domain model.
- Separate data models. These remain consistent, synchronized and decoupled thanks to the domain events. For the read model you can use any technology, from JDBC, ORM systems through NoSQL solutions, since the only purpose is to populate the view with data as quickly as possible. We can have denormalized databases to optimize the reads and avoid complex queries with many unions.
Disadvantages
As there is no silver bullet for every scenario, you should keep in mind these considerations:
- Use CQRS when the domain model is complex. A simple model is not going to benefit from this pattern.
- The learning curve is relatively high and it requires the change of the point of view regarding traditional design.
- Higher infrastructure requirements since we have two models (the read model and the write model).
Conclusion
Perhaps the time has come to change the traditional approach to software development? At the end, it is up to you. The benefits of CQRS are tremendous. It keeps the software maintainable, easily extensible and ready to face new challenges that the future holds. If your next project’s requirements are going to be complex, or you just need high availability and scalability at the application level and you want to grow without losing the agility, don’t hesitate, use CQRS.